
Book Club: Fundamentals of Data Engineering (Chapter 1)
This is first look at a book that seems to be recommended by many as essential for a good foundation in data engineering (DE). So while I go through the hoops of making sure my technical skills are up to speed for a career transition into DE, I’ll also be going through the book here, chapter by chapter.
The book is ostensibly a lot more high-level than the other book I’m reviewing at the moment (High Performance Python by Micha Gorelick and Ian Ozwald - see my review of chapter 1 here), so my notes are relatively few. Now that everyone has breathed a sigh of relief, we can dive in.
What is data engineering?
The first chapter is really about defining the role of a data engineer. There are a few good quotes here, like this from “Data Engineering and Its Main Concepts” by AlexSoft:
Data engineering is a set of operations aimed at creating interfaces and mechanisms for the flow and access of information. It takes dedicated specialists—data engineers—to maintain data so that it remains available and usable by others. In short, data engineers set up and operate the organization’s data infrastructure, preparing it for further analysis by data analysts and scientists.
Others can get a bit more technical (yes, SQL comes up), but they ultimately give their own definition for data engineering as a field and the data engineer role itself:
Data engineering is the development, implementation, and maintenance of systems and processes that take in raw data and produce high-quality, consistent information that supports downstream use cases, such as analysis and machine learning. Data engineering is the intersection of security, data management, DataOps, data architecture, orchestration, and software engineering. A data engineer manages the data engineering lifecycle, beginning with getting data from source systems and ending with serving data for use cases, such as analysis or machine learning.
I think these are both quite nice. It’s hard to talk about something which is popular in tech without it sounding like a bunch of buzzwords that don’t really mean anything, but these tread the line well. In addition to defining it, they really focus on what they call the data engineering lifecycle (mentioned above). This seems to be foundational to the whole book and, at least in the way it is presented here, something the authors have come up with themselves. The core is that data goes through 5 stages:
- Generation
- Storage
- Ingestion
- Transformation
- Serving
These enable downstream endeavours in analytics and data science, rely on upstream processes, and have a handful of core undercurrents:
- Security
- Data management
- DataOps
- Data architecture
- Orchestration
- Software engineer
I hope that leaves you suitably scared that you will be doing at least 6 different jobs here. It’s hard to look at that list and not feel a little daunted. Who is possibly an expert in all of these?! In reality, they go on to essentially say that some aspects of these are involved, but not all.
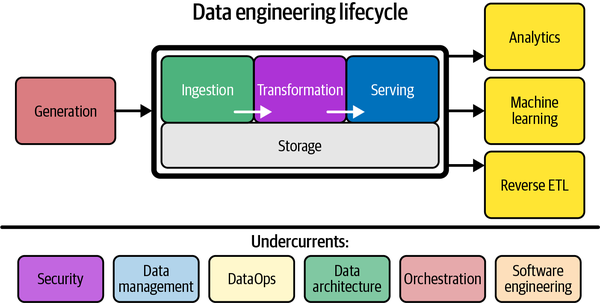
Figure 1-1 from chapter 1 (please don’t sue me O’Reilly)
A brief history of data engineering
The history of the field is really interesting (to me - I like knowing the exact origins of things and how they have developed over time) but not really central to modern data engineering itself. The core takeaway is that this game has been around in some form or another since the 1980s. Even the term data warehouse dates back to 1989, which is quite surprising.
The more recent history is one of an explosion of big data and tooling, followed by a period of consolidation. The authors see the current age as one of progressive abstraction, where workflows are being simplified, tools are taking over a lot of the lower-level manual work, and a data engineering role is increasingly one of stringing-together various high level tools.
Summary
Most of the rest of the chapter expand on details above. There are extensive details on the role of the data engineer in a good team, how this differs from areas like data science and machine learning engineers, and how DEs interact with other roles like project managers. I think this is all useful and helpful to come back to, but again not central, and probably more of-use when you’re in the role.
A lot of this chapter is about definition and taking a nebulous field and role and trying to impose some structure on it. I think it’s helpful, even if some things (like a section titled “the continuum of data engineering roles” which then goes on to give two fairly distinct categories) feel a little artificial. The effort is welcome though - it’s always nice to have a framework to help break down something complex. I think the ideas around “data maturity” and what stage different companies are in their work with data will also be helpful when looking at job postings, so I can have a better sense of what the roles will entail.
Another key takeaway was the line stating that DEs must have “production-grade software engineering chops”. I expected an understanding of software engineering practices to be critical, and that there would be a need to know Python and SQL deeply, and to be able to use things practices and tools like version control, testing, debugging, optimisation and CI/CD pipelines. But I was a little surprised to see that production-grade software engineering skills are essential.
I suppose this stems a little from my inexperience in a production environment, as it looks like the things I already mentioned (debugging/error-handling, testing and validation) are actually some of the main parts in “production-grade software engineering chops”, alongside things like well-organised code. So perhaps it’s more terminology and fear of my inexperience than anything that’s in my way here. I think my plans for working on my Python knowledge already largely align with this, but it’s worth coming back to as I progress.